Framework?
Framework라는 것은 프로그래밍을 하기 위한 어떤 틀, 구조를 의미한다
Java CollectionFramework를 전에 배웠듯이
Map, Set, List 같은 것들은 어떤 데이터를 저장하기 위해 자료구조를 바탕으로 비슷한 유형의 데이터들을
가공하고 처리하기 쉽게 표준화된 방법을 제공하는 클래스의 집합이며
그리고 그 클래스 유형들 중에 기본적인 틀만 존재하는, 추상 메소드만 정의되어 있는 인터페이스가 있고
그 인터페이스들을 구현한 집합체라고 볼 수 있다
개발하려고 하는 애플리케이션을 제로부터 개발하는 것이 아닌
서로 다른 여러 기능이 있는 애플리케이션 간의 통신 같은 것들을
Framework가 라이브러리 형태로 제공해줌으로써
개발자가 애플리케이션의 핵심 로직을 개발하는 것에 도움을 준다
예전에는 서버에 직접 설치를 하고 자바 코드를 일일이 쳐서 개발을 했었지만
이제는 라이브러리 자체에서 필요한 것들을 다 끌어온다
Spring-boot-Library
projectlombok : lombok
Spring-boot-starter-web
- spring-boot-starter-tomcat : 톰캣(웹 서버)
- spring-webmvc : 스프링 웹 MVC
Spring-boot-starter(공통) : 스프링 부트 + 스프링 코어 + 로깅
Spring-boot-starter-test
- junit : 테스트 프레임워크
- mockito : 목 라이브러리
- assertj : 테스트 코드를 편하게 작성할 수 있도록 도와주는 라이브러리
- spring-test : 스프링 통합 테스트 지원
Framework? Library?
그러면 Framework와 Library의 차이는 무엇일까?
애플리케이션 구현을 위해 필요한 여러 기능을 제공한다는 점에선 같지만
제어권이라는 것에 차이가 있다
Library는 개발자가 작성해놓은 코드 내에서 필요한 기능이 있을 때마다
그 라이브러리를 호출해서 사용한다고 하면
Framework는 저것뿐만 아니라 코드에서 보이지 않는 여러 기능들을 한다
(애너테이션이나 Framework 자체에서 지원하는 여러 메소드 기능)
그러니까 Library는 개발자에게 애플리케이션 개발 주도권이 있는 거고
Framework는 개발자가 아닌 Framework 자체에 주도권이 있다고 생각하면 편하다
개발자가 작성한 코드를 이용해서 알아서 애플리케이션 흐름을 만들어내니까
Spring Framework?
그러면 Spring Framework가 무엇인가?
Spring Framework는 Java 기반의 웹 애플리케이션을 개발하는데 필요한 Framework이다
물론 Java 기반의 다른 Framework
Apache Struts2
Apache Wicket,
JSF(Java Server Faces),
Grails 같은 Java나 JVM 기반의 웹 Framework도 있다
개발 생산성을 높이고 유지 보수를 더 효율적으로 하는 것에 대해 초점을 맞추는데
Spring Framework는 이러한 목적의 그 이상을 할 수 있게 해 준다
지금 당장 이 효용성을 체감할 수 없겠지만
학습하고 계속 익숙해지고 확장시켜 나가 보면 언젠가 알 수 있을 것이라고 생각한다
객체 지향 설계 원칙에 알맞은 재사용, 확장이 가능한 애플리케이션 개발 스킬
좋은 성능과 서비스의 안정성이 필요한, 복잡한 기업용 엔터프라이즈 시스템을 제대로 구축하는 능력
이 2가지를 목표로 공부를 해야 할 것이다
POJO (Plain Old Java Object)

Spring 삼각형
POJO를 IoC/DI, AOP, PSA를 통해 달성할 수 있다는 의미의 삼각형이다
POJO라는 것이 무엇인가?
오래된 방식의 간단한 Java 오브젝트이며
무거운 프레임워크들이 종속된 무거운 객체를 만들게 된 것에 반발한 탓에 생겨난 개념이다
기존의 Java 객체 지향 프로그래밍은
상속을 통해 확장을 시키거나 추상 메소드를 사용해서 인터페이스를 구현할 때
만약 애플리케이션의 요구사항이 변경돼서 다른 기술로 변경하려고 한다면
기존의 클래스를 명시적으로 사용했던 부분을 죄다 갈아엎어야 한다
매우 종속적임을 알 수 있는 부분이다
POJO는 특정 Java 모델, 기능, 프레임워크 등을 따르지 않은
특정 기술에 종속되어 동작하는 게 아닌 순수한 자바 객체를 지칭한다
이것을 이용해서 프로그래밍 코드를 작성하는 것을 POJO 프로그래밍이라고 하는데
Java나 Java 스펙에 정의된 것 이외엔 다른 기술이나 규약에 얽매이지 말아야 하고
특정 환경에 종속적이지 않아야 한다
그래야만 객체지향적인 설계를 제한 없이 적용할 수 있기 때문이다
객체지향적인 설계?
객체지향 프로그래밍 OOP에 대해 학습은 했었지만 이건 학습한 기억이 없다
그렇기 때문에 잠깐 살펴보자
SOLID - 객체지향 설계
Single responsibility principle
단일 책임 원칙 : 하나의 클래스는 하나의 책임만 가져야 한다
- 하나의 책임을 가진다는 것은 그 클래스가 책임을 완전 캡슐화를 해야 한다는 말이다
그러니까 어떤 클래스나 모듈을 변경하려는 이유 단 한 가지만 가져야 한다는 말이기도 하다
어떤 출력물을 생각할 때
출력물 내용 때문에 변경될 수 있는 경우가 있고
출력물 형식 때문에 변경될 수 있는 경우가 있다
이 2가지 변경을 보면
전자는 실질적인 데이터의 변경이고
후자는 프레임 구조를 디자인하는 것이라서
서로 매우 다른 원인으로 볼 수 있다
단일 책임 원칙에 의하면 이 문제는
실제로 분리된 2개의 원인, 책임 때문이라서
분리된 클래스나 모듈로 나눠야 하고
이러한 다른 시기, 다른 이유로 변경되어야만 하는
서로 독자적인 이 2가지를 묶는 것이 나쁜 설계라고 보는 것이다
한 클래스에 집중하도록 하는 것이 중요한 이유는
당연하게도 그 클래스를 더 견고하고 정밀하게 만들기 때문일 것이며
위에 예시로 든 출력물의 편집 과정에 만약 변경이라도 일어나게 된다면
같은 클래스 일부의 출력 코드들이 고장 날 위험이 높다
Open/closed principle
개방-폐쇄 원칙 : 소프트웨어 요소는 확장에 열려있지만 변경에는 닫혀 있어야 한다
- 소프트웨어 개발에 사용되는 모듈 중에 하나를 수정해야 한다면
그 모듈을 사용하는 다른 모듈들도 줄줄이 수정을 해야 한다
그러면 이 프로그램은 수정이 어렵다고 말할 수 있고 사용할 가치가 없는 거라고 봐도 무방할 것이다
그렇기 때문에 개방-폐쇄 원칙에 의거해서
시스템 구조 자체를 올바르게 리팩터링 해서 이런 무분별한 수정을 유발하지 않도록 하는 것이 좋고
대신 기능을 추가하거나 변경해야 할 때 기존의 코드들을 건드는 것이 아닌,
새로운 코드를 추가함으로써 추가나 변경이 가능하다
확장에 대해 열려있다 라는 말은
모듈이 하는 일 자체를 변경할 수 있다는 것, 동작을 확장시킬 수 있다는 말이고
수정에 대해 닫혀있다 라는 말은
소스코드나 바이너리 코드를 수정하지 않더라도 모듈 기능을 확장시키거나 변경할 수 있다는 말이다
그러니까 모듈 실행 라이브러리나 어떤 바이너리 형태의 파일을 건드릴 이유가 없다는 것이다
대표적인 예시로 추상화를 들 수 있다
고정되긴 하지만 제한되지 않으며 가능한 동작의 묶음을 표현하는 추상화는
객체 지향 프로그래밍에서 핵심적인 개방-폐쇄 원칙이라고 할 수 있다
Liskov substitution principle
리스 코프 치환 원칙 : 프로그램 객체는 프로그램 정확성을 파괴하지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 한다
- 치환성이라는 것은 객체 지향 프로그래밍 원칙이라고 할 수 있는데
프로그램에서 자료형 S가 자료형 T의 하위형태라면
필요한 프로그램 속성(정확성, 수행업무 같은 것들)의 변경 없이
자료형 T의 객체를 자료형 S의 객체로 교체(치환)할 수 있어야 한다는 원칙이다
아주 유명한 예시를 들어보면
정사각형과 직사각형이 있다
정사각형은 직사각형이지만
직사각형은 정사각형이 아니다
차이를 너비와 높이를 통해 알 수 있다
이걸 클래스로 표현해본다면
직사각형 객체를 상속받아서 정사각형 객체를 만들 수 있을 것이다
직사각형은 너비와 높이를 독립적으로 변경할 수 있다고 해두고
정사각형은 너비와 높이 둘 다 한 쌍으로 변경해야만 한다고 해보자
만약 정사각형 객체가 직사각형을 다루는 곳에서 사용되는 경우에
정사각형 클래스의 할당 메소드를 수정해서 정사각형의 불변 조건 (너비 높이 서로 같음)을 유지하면
이 메소드는 크기를 독립적으로 변경할 수 있다고 설명한 직사각형의 할당자를 위반하는 셈이다
만약 내각이 90도이다 라는 메소드만 가진다고 한다면 LSP를 위반하지 않을 것이고
이건 곧, 자료형 객체의 상호 교환이 가능하다 라는 LSP 원칙을 지킨 것이라고도 볼 수 있다
Interface segregation principle
인터페이스 분리 원칙 : 특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다
- 클라이언트는 자신이 이용하지 않는 메소드에 의존하지 않아야 한다는 원칙이다
구현할 객체에 무의미한 메소드 구현을 방지하기 위해 필요한 것들만 구현하도록 권고하는 것이며
이게 너무 크다면 그 객체 메소드를 작은 인터페이스로 쪼개는 것이 좋다고 말하는 것이다
큰 단위의 인터페이스들을 구체적이고 작은 단위로 쪼개버림으로써
클라이언트들이 꼭 필요한 메소드들만 이용할 수 있게 한다
이걸 우리는 역할 인터페이스라고 부른다
분리 원칙을 통해서 시스템 내부 의존성을 약화시켜서 리팩터링, 수정, 재배포를 쉽게 할 수 있다
예시로
버전이 다른 스마트폰을 들 수 있다
상대적으로 버전이 낮은 구형 스마트폰은 버전이 높은 최신 스마트폰보다 할 수 있는 기능의 개수가 적다
최신 스마트폰의 경우 주어진 스마트폰 객체가 모두 필요하기 때문에 ISP를 만족하지만
구형 스마트폰은 그 기능을 수행할 수 없기 때문에 필요하지도 않은 메소드들이 있는 것이고 그건 낭비라고 할 수 있다
그렇기 때문에 공통적으로 최신과 구형 모두 구현이 되는 메소드들을 정의하되,
최신 스마트폰에 들어갈 기능 메소드들은
최신 기능 인터페이스를 따로 구현시켜서 각각 전부 상속시키면 된다
이는 위에서 말한 인터페이스를 작은 단위로 쪼갠다고 말한 것의 예시라고 볼 수 있다
Dependency inversion principle
의존 관계 역전 원칙 : 추상화에 의존하는 것이지 구체화에 의존하면 안 된다
- 이게 무슨 말인가 하면
구체적이고 한정적인 객체보다는 추상적이고 유연한 객체, 인터페이스를 사용해야 한다는 말이다
객체로 구현해야 할 것과 인터페이스로 구현해야 할 것들을 적절하게 구분해서 올바른 의존관계를 가지도록 만들어야 한다
예시로
어떤 한 사람 A에게 한글 사용이라는 클래스로부터 객체를 만든다고 해보자
A한테 수많은 언어 중 한글을 사용하는 다양한 기능, 메소드를 부여한다고 했을 때
A는 한글을 가지고 한글로 된 책을 읽을 수 있거나 대화를 할 수 있을 것이다 (읽기, 말하기 같은 인스턴스가 생성될 것)
그런데 세상에는 한글 말고도 다양한 언어가 있다
A가 한글 말고도 영어를 쓰려고 한다면 어떨까?
A의 인스턴스를 생성할 때 이미 한글이라는 의존성을 가지기 때문에
어떤 인스턴스를 생성하더라도 한글에 국한될 수밖에 없다
그래서 영어로 바꾸려고 한다면 이 근본적인 클래스 자체를 갈아엎어야 할 것이다
당연히 개방-폐쇄 원칙도 위배할 것이고
A의 사용 언어를 바꾸려고 할 때마다 이 짓을 반복해야 할 것이다
그렇기 때문에 애초에 보다 더 추상적인 고수준의 상위 개념에 의존할 필요가 있다는 말이다
그럼 이렇게 바꿀 수 있다
좀 더 고수준의 모듈인 "언어"라는 인터페이스를 생성을 하고
추상 메소드로 여러 언어 사용이 가능한 언어 객체는 이 인터페이스를 상속받게 될 것이다
그러면 한글뿐만 아니라 영어, 일본어 등등
"언어"를 상속하는 모든 객체를 다룰 수 있게 되는 것이다
기존에는 A가 한글을 사용하는 것에 의존하고, 한글은 그 무엇으로도 의존하지 않는 클래스였는데
추상적인 "언어" 라는 인터페이스에 의존하게 되었고
이것을 의존의 방향이 역전되었다 라고 말한다
이러한 SOLID가
POJO를 사용하는 핵심적인 이유라고 할 수 있다
또 다른 필요한 이유를 들자면
위에서 언급한 대로
1. 특정 환경이나 기술에 종속적이지 않고 재사용이 가능하고 확장 가능한 유연한 코드를 작성할 수 있다
2. 저수준 레벨의 기술과 환경에 종속적인 코드를 애플리케이션 코드에서 지움으로써 코드가 클린 해진다
3. 그렇기 때문에 디버깅이 수월해진다
4. 그렇기 때문에 테스트 또한 단순해진다
이러한 POJO 프로그래밍 코드를 작성하기 위해
Spring에서는 IoC/DI, AOP, PSA 기술을 지원한다
IoC (Inversion of Control) / DI (Dependency Injection)
IoC (Inversion of Control)
제어 반전, 제어의 역전
일반적으로 프로그램의 흐름은 main() 메소드와 같이 프로그램이 시작되는 지점에서
다음에 사용할 오브젝트를 결정하고,
결정한 오브젝트를 생성하고,
만들어진 오브젝트에 있는 메소드를 호출하고,
그 오브젝트 메소드 안에서 다음에 사용할 것을 결정하고 호출하는 식의 작업이 반복된다
이런 프로그램 구조에서 각 오브젝트는 프로그램 흐름을 결정하거나
사용할 오브젝트를 구성하는 작업에 능동적으로 참여한다
그러나, IoC개념에서는 오브젝트가 자신이 사용할 오브젝트를 스스로 선택하지 않는다
당연히 생성하지도 않으며 자신이 어떻게 만들어지고 어디서 사용되는지를 알 수 없다
그러한 이유는, 모든 제어 권한을 자신이 아닌 다른 대상에게 위임하기 때문이다
프로그램의 시작을 담당하는 main()과 같은 엔트리 포인트를 제외하면
모든 오브젝트는 이렇게 위임받은 제어 권한을 갖는 특별한 오브젝트에 의해 결정되고 만들어진다
이번 학습의 경우, 스프링을 의미한다
객체를 생성하고 그 객체에 의존성을 주입을 하고
의존성 객체 메소드를 호출을 하는
모든 의존성 객체를 스프링이 실행될 때 만들어주고 필요한 곳에 의존성을 주입시킴으로써
Bean이라고 하는 싱글톤 패턴 특징을 가지고
제어 흐름을 개발자가 아닌 스프링 자체에 맡겨서 작업을 처리하는 구조라고 할 수 있다
여기서 나오는 말들은 다 뒤에서 학습할 예정이다
그렇기 때문에
Framework도 IoC 개념이 적용된 대표적인 기술이라고 할 수 있다
위에서도 언급했던 대로 Framework는 Library와 차이가 있다
Library를 사용하는 애플리케이션은 흐름을 직접 제어한다고 했다
동작하는 중에 필요한 기능이 있을 때 능동적으로 사용한다는 말이다
그리고 Framework는 애플리케이션 소스 코드가 Framework에 의해 사용된다고 했다
보통 Framework위에 개발한 클래스를 등록해두고, Framework가 흐름을 주도하는 중에
개발자가 만든 애플리케이션 소스코드를 사용하도록 만든다는 말이다
객체의 의존성을 역전시켜서
객체 간의 결합도를 줄이고 보다 더 유연한 코드를 작성할 수 있게 만들어서
가독성을 높이고, 코드의 중복을 줄이며
효율 높은 유지 보수를 할 수 있다
그렇기 때문에
Framework에는 IoC 개념이 적용되어 있고, 그래야만 한다
애플리케이션 소스코드는 Framework가 짜 놓은 틀에서 수동적으로 동작해야 할 필요성이 있다
정리하자면,
설계 목적상 제어 반전의 목적은
작업 구현 방식, 작업 수행 자체를 분리(객체지향 원리 적용)
외부 프로그램과 모듈의 결합에 대한 고민 없이 모듈 자체의 목적에 집중할 수 있으며
다른 시스템이 어떻게 작동할지에 대한 고민 또한 할 필요 없이 미리 정해진 협약대로만 작동하게 하면 되고
이 모듈을 바꾼다고 하더라도 다른 시스템에 부작용(외부에서 데이터를 변경하려고 하는 경우)
을 끼치지 않게 하기 위함이다
이러한 IoC의 개념은 DI로 이어진다
DI (Dependency Injection)
IoC 개념을 조금 더 구체화시킨 것이라고 보면 되는 DI는
의존성 주입이라는 의미다
여기서 의존성이라는 것은 객체지향 프로그래밍에서 객체 간 의존성을 의미한다
의존성이라는 것은 무엇인가?
어떠한 요소가 어떠한 요소를 필요로 한다
라고 할 때 의존성이 있다고 한다
예시로,
서비스로 사용하는 객체, 클라이언트가 어떤 서비스를 사용할 것인지 정하는 것보다는
클라이언트에게 무슨 서비스를 사용할 건지 말해준다
여기서 주입은 서비스를 사용하려는 객체, 클라이언트로 전달한다 라는 의미이기도 하다
의존성 주입이라는 것은 결국
객체의 생성과 사용의 관심을 분리시키는 것에 핵심이 있으며
애플리케이션이나 클래스가 객체 생성 방식과 어떻게 독립적일 수 있을지
객체 생성 방식을 분리된 구성 파일에서 어떻게 지정할 수 있을지
애플리케이션이 다른 구성을 어떻게 지원할 수 있을지
이러한 문제들을 해결하는 데 사용한다
매우 많은 경우가 있겠지만 간단하게 아래의 예시를 들어보겠다

여기 A라는 클래스와 B라는 클래스가 있다
A는 B에 의존한다
다시 말해, A가 B를 멤버 변수나 로컬 변수로 가지고 있거나 파라미터로 전달되거나 B의 메소드를 호출하는 것을 의미한다
만약 B가 변경되면 A는 B를 강하게 의존하고 있기 때문에 컴파일 에러가 난다거나 예기치 못한 동작을 하게 된다
이런 의존성은 A를 재사용하기 어렵게 만들기 때문에 A는 컴포넌트,
소스 코드 수정 없이 다른 프로젝트에서 바로 재사용이 가능한 수준의 모듈이 될 수 없다
A만 재사용하기 위해선 A에서 B를 사용하는 부분을 수정할 필요가 있다
좀 더 구체적인 예시를 들어보면
public class Com_const {
public static void main(String[] args) {
Comconst comconst = new Comconst(
"AMD Ryzen 3", "Windows 10", "gtx 1060 ti");
System.out.println(
"내 컴퓨터는 " + comconst.setCPUName() + " 라는 CPU를 사용하고 "
+ "운영체제는 " + comconst.setOsName() + ", " + comconst.setVgaName()
+ " 이라는 그래픽 카드를 장착하고 있다");
}
}
class Comconst{
private String CPUName;
private String os;
private String vga;
public Comconst(String CPUName, String os, String vga){
this.CPUName = CPUName;
this.os = os;
this.vga = vga;
}
public String setCPUName(){
return CPUName;
}
public String setOsName(){
return os;
}
public String setVgaName(){
return vga;
}
}메인 메소드에선 new로 comconst 객체를 직접 생성했다
Com_const 클래스는 comconst를 의존하고 있으며
Com_const 클래스에서 직접 comconst 클래스를 생성해서 사용한다
반면,
아래 Comconst 클래스에서는 생성자를 이용해 객체를 사용한다
직접 생성하는 것이 아니고 외부에서 생성된 객체를 setter()나 생성자를 통해 사용한다
이렇게 생성자를 이용해서 의존성을 주입시키는 것이 DI(Dependency Injection)라고 할 수 있다
new로 직접 생성해서 사용하는 경우
나중에 수정할 사항이 생길 때
.java 전체 파일을 갈아엎어야 하는 불상사가 발생한다
그러나 외부에서 생성된 객체를 setter()나 생성자를 통해 사용을 하게 되면
손쉽고 효율성 있게 확장할 수 있다
스프링은 다른 객체들이 사용하거나 다른 서비스를 위해 사용할 수 있는 클래스를
어떤 컨테이너 형태로 기능을 제공해준다
어떤 A라는 객체에서 B, C 객체를 의존, 그러니까 사용하고 필요로 할 때
A 객체에서 직접 생성을 하는 것이 아니라
외부 Bean 컨테이너에서 생성된 B, C 객체를 주입시켜서 setter()나 생성자를 통해 사용할 수 있다는 말이다
SOLID의 D
Dependency inversion principle
의존관계 역전 원칙과 부합하는 내용이기도 하다
스프링에서 Bean 컨테이너를 활용, 외부에서 객체를 주입시킨다는 개념은
다음 시간에 블로깅하면서 더 자세하게 다룰 것이다
AOP(Aspect Oriented Programming)
개발을 진행하다 보면
애플리케이션 전체적으로 공통 사용 기능들이 있는 것을 알 수 있는데
이런 것들을 공통적인 관점(Cross-cutting concern) 또는 부가적인 관점이라고 한다
그리고 주목적을 달성하기 위한 핵심 로직에 대한 관점을 핵심적인 관점(Core concern)이라고 한다
공통적인 부분과 핵심적인 부분을 어떤 로직을 기준으로 나누어서 보고
그걸 각각 모듈화 하겠다고 하는 것을 AOP라고 한다
여기서 모듈화는 공통 로직이나 기능을 하나의 단위로 묶는다는 것을 의미한다
핵심적인 관점은 우리가 개발하는 데 있어서 가장 핵심이 되는 비즈니스 로직이고
부가적인 관점은 핵심 로직을 실행하기 위해 이루어지는 DB 연결, 로깅, 파일 입출력 같은 것을 예시로 들 수 있다
AOP에서 각 관점을 기준으로 로직을 모듈화 한다는 것은 코드들을 잘게 나눠서 모듈화 하겠다는 의미이다
공통 관심 사항을 모아서 Aspect(공통 사용 관점을 모듈화 한 것으로, 부가 기능을 모듈화함)
로 모듈화하고 핵심적인 비즈니스 로직에서 분리해서 재사용하겠다 라는 것이
코드의 간결성을 유지하고 객체지향 설계 원칙에 맞는 코드를 구현하고 그 코드를 재사용한다는,
AOP의 진정한 취지라고 할 수 있다
모든 AOP 기능을 제공하는 게 아니고 스프링 IoC랑 연동해서 엔터프라이즈 애플리케이션에서 가장 흔한
중복 관련 문제나 객체 간 복잡도가 높아진다는 것들에 대한 해결책을 지원하는 것이 목적이다
간단한 예시를 들어보면
import java.util.logging.Level;
import java.util.logging.Logger;
import org.springframework.util.StopWatch;
public class AopPractice {
private final static Logger log = Logger.getGlobal();
public void measurement(){
StopWatch stopwatch = new StopWatch("measurement");
stopwatch.start();
zeroTosixty();
stopwatch.stop();
log.setLevel(Level.INFO);
log.info("측정 시간 : " + stopwatch.getTotalTimeMillis() + "ms");
}
private void zeroTosixty() {
...
}
}
zeroTosixty() 라는 자동차 제로백을 위한 가속 메소드가 있다고 하자
물론 이게 실제로 어떤 구현 소스코드를 가지고 있는 건 아니지만
Aop를 이해하기 위해 예시로 그런게 있다고 설정해두는 것이다
만약, 여기서 zeroTosixty() 메소드가 실행되는 시간,
즉 가속도를 내서 100km/h 까지 속도를 내는 이 메소드에 대한 시간을
제로백을 측정하기 위해 스탑워치를 찍어달라는 요청이 들어오게 된다면
저렇게 measurement() 메소드를 만들어서 코드를 작성할 수 있다
비즈니스에 실제로 필요한 로직은 zeroTosixty() 메소드 밖에 없고
나머지는 부가적인 기능일뿐이다
그리고 또 새로운 요구사항, 다른 자동차의 zeroTosixty2()를 만들어 달라는 요구사항이
들어온다면
그냥 여태 해왔던 것 처럼 그냥 zeroTosixty2()를 만들고 또 스톱워치 코드를
작성하면 그만이다
그런데 이 코드는 문제점이 있다
N개의 메소드가 있을 때 N개의 스톱워치 메소드가 필요할 것이고
log 출력에서 log 내용을 바꿔야 하는 일이 발생하면 또 N번 작업을 해야 한다
그리고
비즈니스 로직과 기능적 역할을 하는 소스코드가 같은 class안에 혼재될 수 밖에 없고
시간 측정 스탑워치 메소드 또한 중복이 되어버린다
여기서 Spring의 AOP가 효율적으로 쓰일 수 있다
공통되게 사용되는 기능적인 역할하는 코드를 재활용해서 사용할 수 있도록 만들어 줄 것이다
AOP를 사용하게 되면 class안에 주요 핵심 로직만 남길 수 있고
나머지 기능적인 코드들은 다른 class로 뺄 수 있게된다
실제 AOP 적용하는 것은
뒤에 더 자세히 학습하면서 실습하겠다
PSA(Portable Service Abstraction)
일관된 방식의 기술의 접근 환경을 제공하는 추상화 구조
추상화 계층을 사용해서 어떤 기술을 숨기고 편의성을 제공해주는 것이라고 말할 수 있다
POJO 원칙을 따른 Spring의 기능,
Spring에서 작동하는 Library들은 POJO 원칙을 지키게끔 PSA 형태로 추상화되어 있음을 의미하기도 한다
그러니까 잘 짜인 인터페이스라는 말이다
PSA가 적용되어 있으면 내가 짜 놓은 코드를 굳이 바꾸지 않고 다른 기술로 간편하게 바꿀 수 있어서
확장성이 좋고 어떤 기술에만 특화되어 있지 않은 코드를 의미한다
Spring Web MVC, Spring Transaction 같은 다양한 PSA가 있다
이중에 Spring Transaction은 @Transactional 애너테이션을 선언하는 것만으로도 별도 추가 코드 없이
트랜잭션 서비스를 사용할 수 있다
그러니까, 내부적으로 트랜잭션 코드가 추상화돼서 숨겨져 있는 것이다
Transaction, 어떤 데이터베이스 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위를 말한다
데이터베이스 부분 블로깅에서 다시 언급할 것이다
아무튼 이 트랜잭션을 예시로 들면
Java와 DB가 통신을 하기 위해서는 DB Connection을 맺어야 하고 그 뒤에 트랜잭션을 시작한다
쿼리 실행 후 결과에 따라서 Commit이나 Rollback을 하고 마지막에 DB Connection을 종료하며 마무리하는 구조다
public void dbTransaction() throw Exception {
Connection c = DataSourceUtils.getConnection(dataSource);
// DB Connection 생성
TransactionalSynchronizationManager.initSunchronization();
// 트랜잭션 시작
try {
// * DB 쿼리 실행
c.commit();
// 트랜잭션 커밋
} catch(Exception e) {
c.rollback();
// 트랜잭션 롤백
throw e;
} finally {
DatasourceUtils.releaseConnection(c, dataSource);
TransactionSynchronizationManager.unbindResource(dataSource);
TransactionSynchronizationManager.clearSynchronization();
// DB Connection 종료
}
}
* 표시된 부분, DB 쿼리 실행을 제외하고는 @Transactional에서 제어해주는 부분이다
* 부분, DB 쿼리 실행하는 부분은 직접 구현하는 비즈니스 메소드가 될 것이고
저 부분을 제외하면 AOP를 통해 구현된다
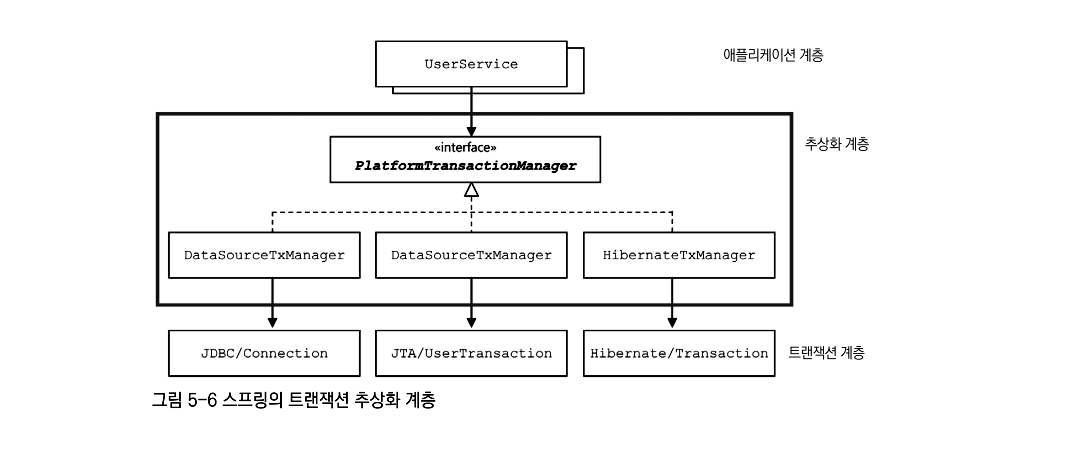
위의 이 사진에 보면 Spring의 트랜잭션 매니저 관계를 나타내고 있는데
Spring의 @Transactional은 각 트랜잭션 매니저를 따로 구현하고 있는 게 아니라,
최상위 플랫폼 트랜잭션 매니저를 이용하고
필요한 트랜잭션 매니저를 DI로 의존성을 주입받아 사용한다
이렇듯
PSA는 어떤 서비스를 이용하기 위한 접근 방식을 일관된 방식으로 유지함으로써
애플리케이션에서 사용하는 기술이 변경된다 하더라도 최소한의 변경만으로 요구 사항을 반영할 수 있다
추상화된 상위 클래스를 일관되게 바라보면서 하위 클래스의 기능을 사용하는 것이라고도 말할 수 있다
더 자세한 내용은 후에 스프링 실습에서 이 개념이 나올 때 예제를 통해 자세히 공부할 것이다
'Spring' 카테고리의 다른 글
| [Spring Core] DI (Dependency Injection) - ① (0) | 2022.08.15 |
|---|---|
| [Spring Core] DI 실습하기 전 선행 실습 과제 (0) | 2022.06.19 |


댓글